- Register and/or log in to the Firebolt Workspace.
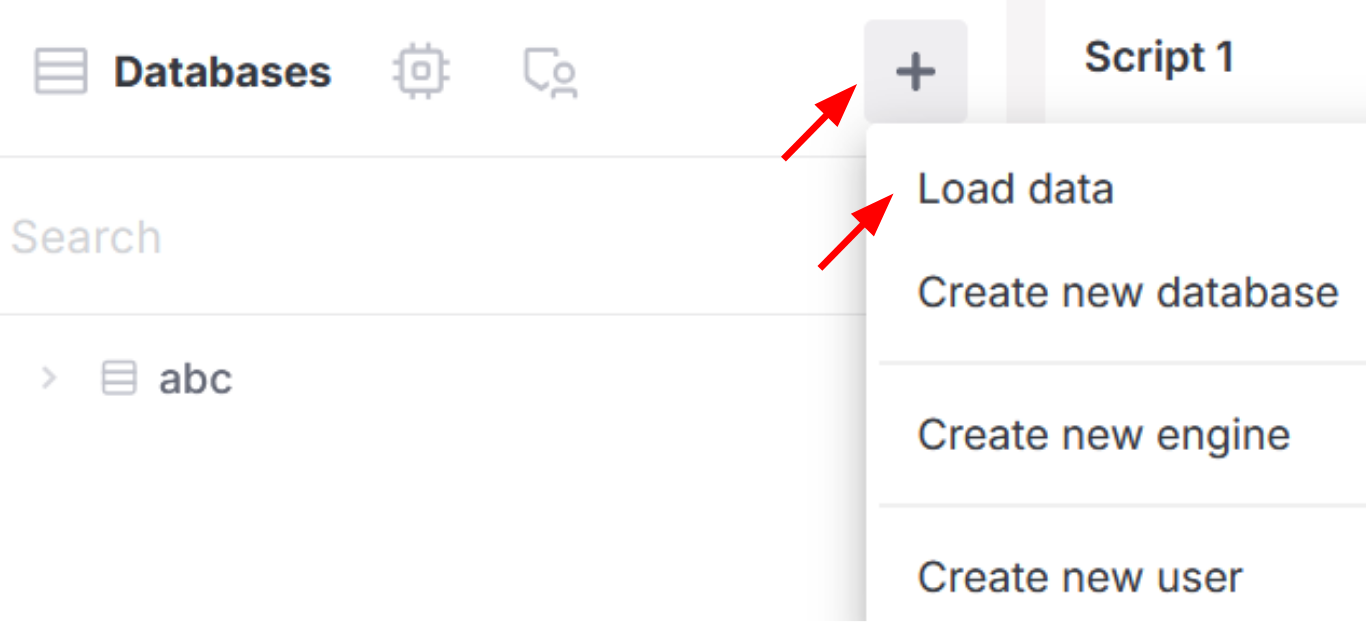
- Select the (+) icon from the left navigation pane next to Databases.
- Select Load data from the drop-down menu, as shown in the following image:
Select an engine

Select an engine to load data. If the engine that you want to use already exists, select it from the dropdown list next to Select engine for ingestion. Otherwise, select Create new engine from the dropdown list, and do the following:
- Enter a name in the New engine name text box.
-
Select an engine size from the drop-down list next to Node type. Consider the following when creating a new engine:
- If you are loading data and using Firebolt for the first time, use the smallest engine size (S) and a small dataset to try out Firebolt’s capabilities. Refer to the Get Started guide for more information.
- If you want to load larger datasets, and a S engine provides insufficient performance, Firebolt recommends scaling out, or adding more nodes, first, as shown in the following diagram.
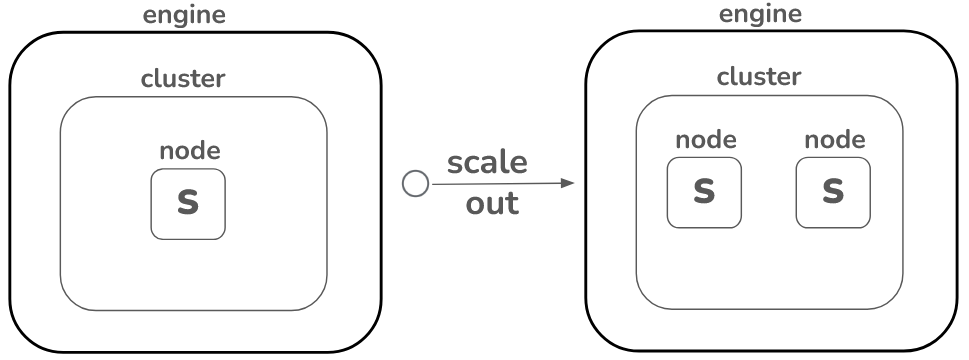
Scaling out can enhance performance for workloads with many similarly sized files, but it also increases billing costs. Small and medium engines are available for use right away. If you want to use a large or extra-large engine, reach out to support@firebolt.io. For more information, see Sizing Engines. - Select the number of compute nodes to use to load your data next to Number of nodes. A node is an individual compute unit within a compute cluster.
- Using more than one node allows Firebolt to load your data and perform operations on your data in parallel on multiple nodes within a single cluster, which can speed up the data loading process.
- A higher number of nodes also means increased costs for compute resources. You can see the total cost per hour for your selection under Advanced settings, given in Firebolt Units (FBU). Each FBU is equivalent to $0.35 US dollars per hour. Find the right balance between cost and speed for your workload. You must use at least one node.
-
Select the number of clusters next to Number of clusters. A cluster is a group of nodes that work together. The following apply:
- If you increase the number of clusters, you will add the number of compute nodes that you selected for each added cluster. You can see the total cost per hour for your selection under Advanced settings, given in Firebolt Units (FBU). Find the right balance between cost and speed for your workload. You must use at least one cluster.
- Select the down arrow next to Advanced settings for more options for your engine including setting a time to stop the engine after a period of inactivity.
Set up AWS connection

A. Using public data that do not require access credentials
- If the data is public and no credentials are needed, simply provide the URL of your Amazon S3 bucket and select Next Step.
B. Using Private Data (Credentials Required)
If the data requires credentials for access, you must provide them so that Firebolt can retrieve it from AWS on your behalf. You can choose either Static Credentials or Assume Role Authentication.- Use static credentials for simplicity and persistent access when security risks are low, and if your environment requires minimal configuration.
- Use AssumeRole Authentication** for enhanced security, temporary access, and dynamic role management, particularly in environments requiring fine-grained permissions or cross-account access.
1. Static Credentials
- Provide the URL for your Amazon S3 bucket.
- Enter your AWS Key ID and AWS Secret Key.
- For authentication:
- Select Access Key ID & Secret Key as your authentication method.
- The AWS Key ID is a 20-character string associated with an AWS user or IAM role (e.g.,
AKIAIOSFODNN7EXAMPLE). - The AWS Secret Key is a 40-character string linked to the AWS Key ID (e.g.,
wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY). - Optionally, you can also specify an AWS Session Token.
- For more information about these credentials, see Create Access Key and Secret ID in AWS.
- Select Next Step.
2. Assume Role Authentication
- Select IAM Role as your authentication method.
- Select Create an IAM role. To allow Firebolt to read and write to your Amazon S3 bucket using dynamic credentials, you must do the following:
- Create an IAM Role.
- Define an AssumeRole Policy.
- After the role is created in your AWS account and the trust policy is attached, copy the Amazon Resource Name (ARN) of the role to your clipboard.
- Paste the ARN into the Amazon Resource Name field in Firebolt.
- Select Next Step.
3. Using Firebolt’s Test Dataset (If You’re Not Ready with Your Own Data)
If you don’t have your own data ready, you can use Firebolt’s sample dataset from the fictional company “Ultra Fast Gaming Inc.”:- Use the following Amazon S3 bucket URL:
s3://firebolt-publishing-public/help_center_assets/firebolt_sample_dataset/.
- Select Next step.
Select data to ingest

- Select the data file that you want to load. Firebolt’s Load data wizard currently supports files in both CSV and Parquet formats. The contents of your S3 bucket are shown automatically along with their object type, size, and when the object was last modified.
- Enter text or a prefix into the search field above FILE NAME to filter the list of objects. You can enter either part of the object’s name or the full prefix that it starts with.
- Select one file. Firebolt does not support selecting multiple files, or selecting folders.
- If you are using Firebolt’s test data, select box next to
levels.csv. - Select Next step.
Set up destination

Specify the table inside a database that you want to load your data into.
-
You can either select an existing database from the drop-down list next to Select database or Create new database.
- If you created a new database, enter a new database name and a new table to load your data into. Select Next step.
- If you selected an existing database, select the table in the database from the drop-down list next to Select table, or Create new table and provide a new table name.
- Select Next step.
Format data

A default formatting and error handling scheme shows a preview of your data. You can change the default configuration using the following options:
-
Toggle off Use default formatting to show custom formatting options. You can specify options including different file delimiter, quote character, and escape character.
- Enter a new value in the text box or select an option from the drop-down arrow next to the option that you want to change.
- After each change, the data preview changes to reflect your selection.
-
Toggle off Use default error handling to show the following additional error handling options:
-
You can specify a file to write errors to. Enter the name of the file that you want to write including the URL address for an Amazon S3 bucket that contains that file, and your AWS credentials. Firebolt will use these credentials to write an error file on your behalf. The output file should be in the following format:
-
Max errors per file - Specify the percentage of errors you want to allow during data loading. By default, the maximum is set to
0%, meaning any error will stop the loading process. If you wish to continue loading despite errors, set Max errors per file to a non-zero value. For example, entering10%or10allows the process to continue until errors affect10%of the rows.
-
You can specify a file to write errors to. Enter the name of the file that you want to write including the URL address for an Amazon S3 bucket that contains that file, and your AWS credentials. Firebolt will use these credentials to write an error file on your behalf. The output file should be in the following format:
- Select Next step.
Map data

Map the values in your data to columns into the target table. Firebolt automatically detects the schema of your data and displays information including the detected column names, type, and a preview of the data in the next window. By default, each column has a checkbox next to its name. Deselect the box if you don’t want to load the column. You can adjust the schema for the following items:
- Type - you can change the data type of the column.
-
Nullable - toggle this switch to
ONif the columns in your data can containNULLvalues. If this value is toggled off for a column, and that column containsNULLvalues, then the wizard will generate an error and stop loading. -
Primary index - toggle this switch to
ONfor the columns you want to include in your primary index.-
One of Firebolt’s key optimization strategies is to use a primary index that ties to columns that are used frequently in
WHERE,JOIN,GROUP_BY, and other clauses used for sorting. Selecting the best primary index, which is a sparse index, can reduce query run times significantly by reducing the data set that the query scans. A primary index also allows Firebolt to manage updates, deletions and insertions to tables and provide optimal query performance.
-
It’s best if you choose a primary index based on knowledge about your data and query history. If you don’t know which column(s) to select, you can use Firebolt’s suggested primary indexes by keeping Automatically assign primary indexes checked, as shown in the following image:

Using Firebolt’s suggested primary index is preferable to having none. In the absence of a query history, Firebolt prioritizes choosing a column for the primary index in the following order: a datetime or timestamp column, a column with low cardinality, or the first column. -
If you include multiple columns as a composite primary index, they will be added in sort order. For example, if you select
column_1first, then selectcolumn_3, thencolumn_3will be added as a primary index aftercolumn_1. This meanscolumn_1will be used first as a sparse index, followed bycolumn_3. If you choose more than one primary index, the order of sorting appears next to the toggle switch under the Primary Index column. In the previous example, the number1appears next tocolumn_1and a number2appears next tocolumn_3. To achieve optimal results, choose indexes in the ascending order of their cardinality, or the number of unique values. Start with the column that has the lowest number of unique values as your first primary index, followed by the column with the next cardinality. For more information about how to choose a primary index, see Primary index.
-
One of Firebolt’s key optimization strategies is to use a primary index that ties to columns that are used frequently in
- Select Next step.
Review configuration
The Review configuration window displays your selections in SQL code. If you want to change the configuration, you must go back through the Load data wizard workflow to the section that you want to change and amend your selection. You cannot edit the SQL code in the Review configuration window.- Select Run ingestion to load your data. The Load data wizard completes and your configuration will run in the Develop Space inside the Firebolt Workspace. The main window in the SQL editor contains the SQL script that configures your load data selections, and may contain several queries.
View results and query statistics

- View information about your query in the Statistics tab. This information contains the status of the query, how long it took to run, and the number of rows processed during the data loading job.
-
View metrics in the Query Profile tab for each operator used in your query. Select an operation to view metrics. These metrics include the following:
- The output cardinality - the number of rows each operator produced.
- The thread time - the sum of the wall clock time that threads spent to run the selected operation across all nodes.
- The CPU time - the sum of the time that threads that ran the operator were scheduled on a CPU core.
- The output types - the data types of the result of the query.
- View monitoring information including the percent CPU, memory, disk use and cache read in the Engine monitoring tab. Information is shown from the last 5 minutes by default. Select a different time interval from the drop-down menu next to Last 5 minutes. You can also select the Refresh icon next to the drop-down menu to update the graphical information.
-
View detailed information associated with each query in the Query history tab. This information includes the query status, start time, number of rows and bytes scanned during the load, user and account information. You can do the following:
- Select the Refresh icon to update the query history and ID.
- Select the filter icon ( ⫼ ) to remove or add columns to display.
- Select the More options icon ( ⋮ ) to export the contents of the Query history tab to a JSON or CSV file.